略难的题,高频题,在各个层级的面试里面都是高频题目。
回答这个问题,要把重点放在渐进式 rehash 上,这也是一个难点,并且你可以结合自己了解的别的类似结构进一步讨论,比如说语言层面上的哈希表。
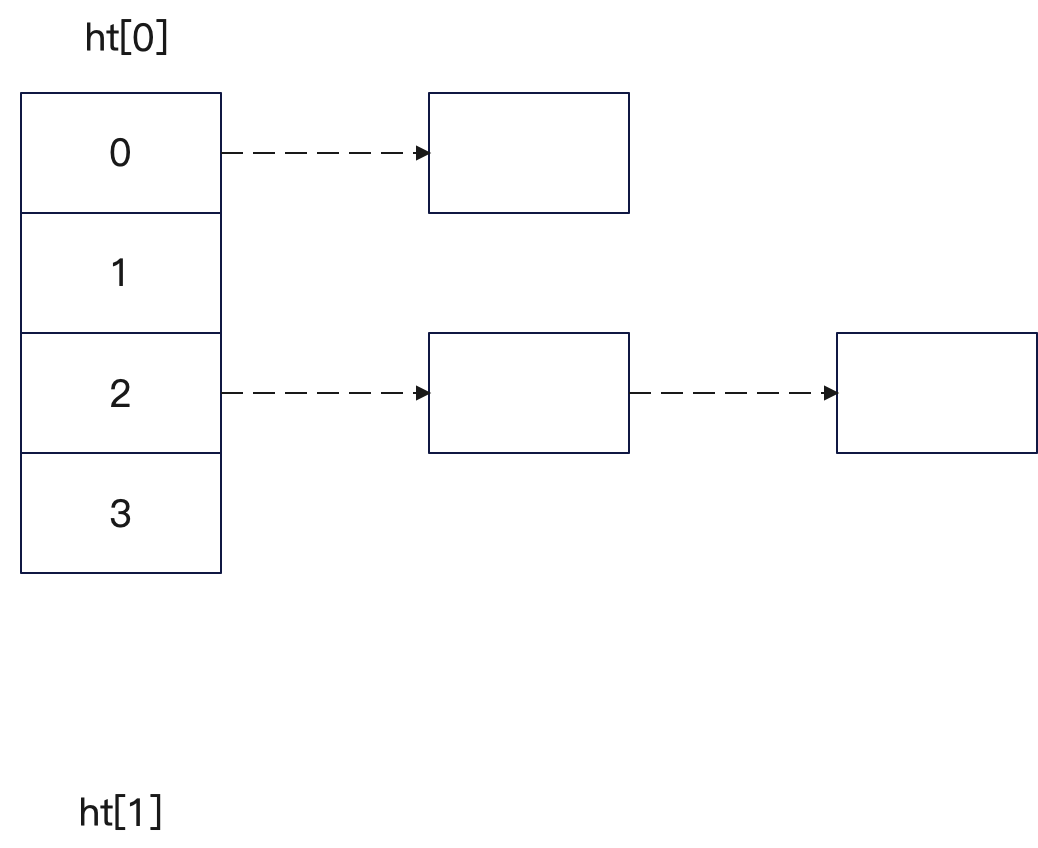
Redis 的 hashtable 的结构,一句话就能说清楚,使用拉链表解决哈希冲突的双表结构。整个结构如下图:
从上图看你就懂什么双表是什么意思了,也就是 Redis 里面说的 hashtable 实际上是由两个典型的哈希表组成的,对应的就是 ht[0] 和 ht[1] 这两个。
而拉链法解决冲突,你要是学过数据结构就能知道它的结构,就是一个数组 + 链表的混合结构。Redis 使用 MurmurHash2 计算哈希值,哈希值除以数组长度的余数,就是数组下标,元素会放在这里。
而 Redis 里面使用 2 的幂作为数组的长度,也就是我们说的容量,所以取余的过程可以变成一个幂操作。
当发生哈希冲突时使用拉链法将新的键值对加在链表头,以加快速度。
MurmurHash2 读起来有点像是 meme hash,也就是猫猫 meme 的 meme,哈哈
所以 Redis 的 hashtable 本身没什么好说的,唯一值得说的就是它为啥用 ht[0] 和 ht[1] 的混合结构?答案就是为了渐进式 rehash。
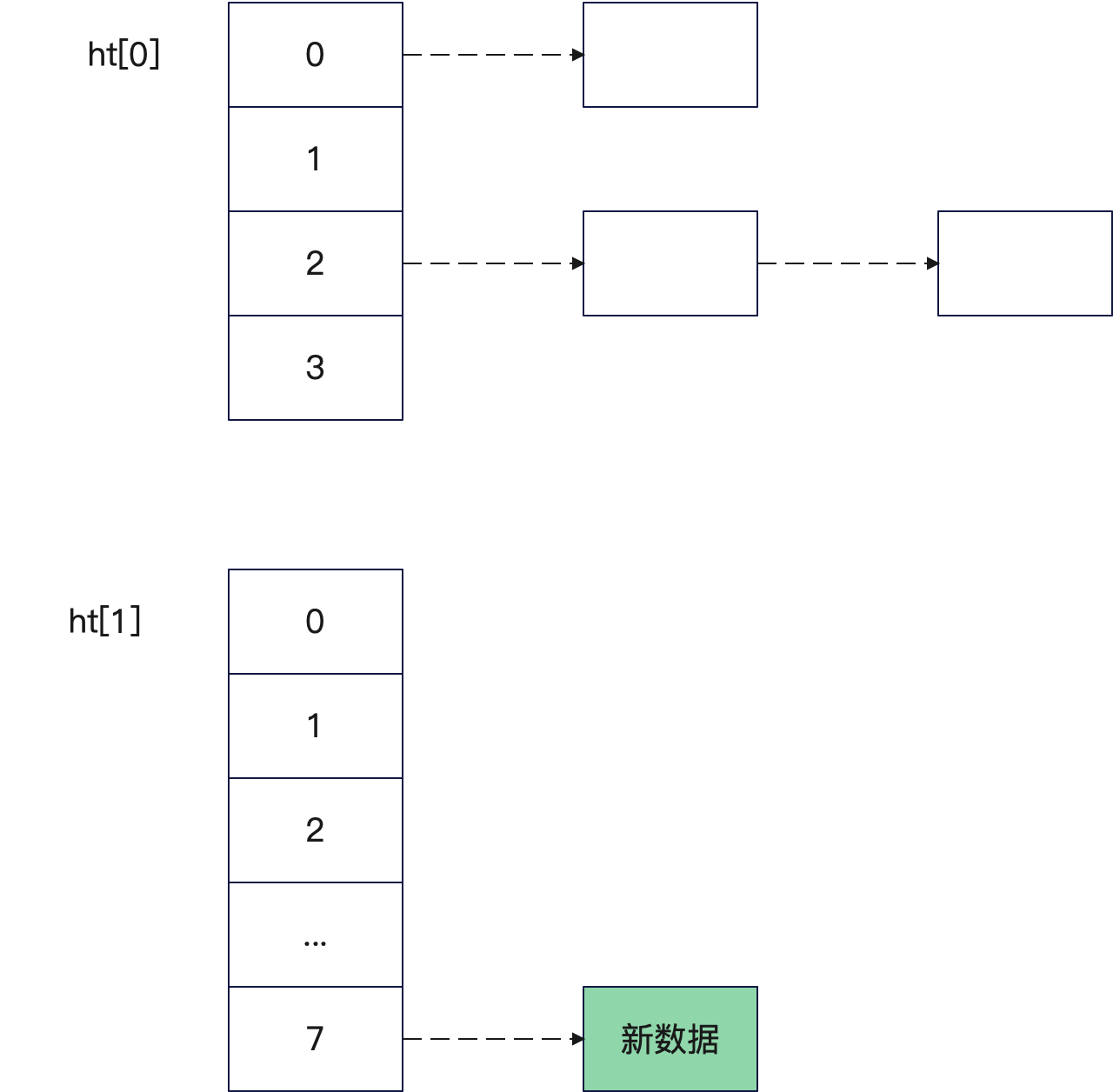
即 Redis 中的 ht[0] 和 ht[1] 实际上对应了新旧两张表,当出现扩容(或者缩容)的时候,Redis 并不是直接在 ht[0] 上扩容。而是 ht[1] 创建一个新的,而后在增删改查的时候逐步挪过去。如下图,是 ht[1] 准备扩容的时候:
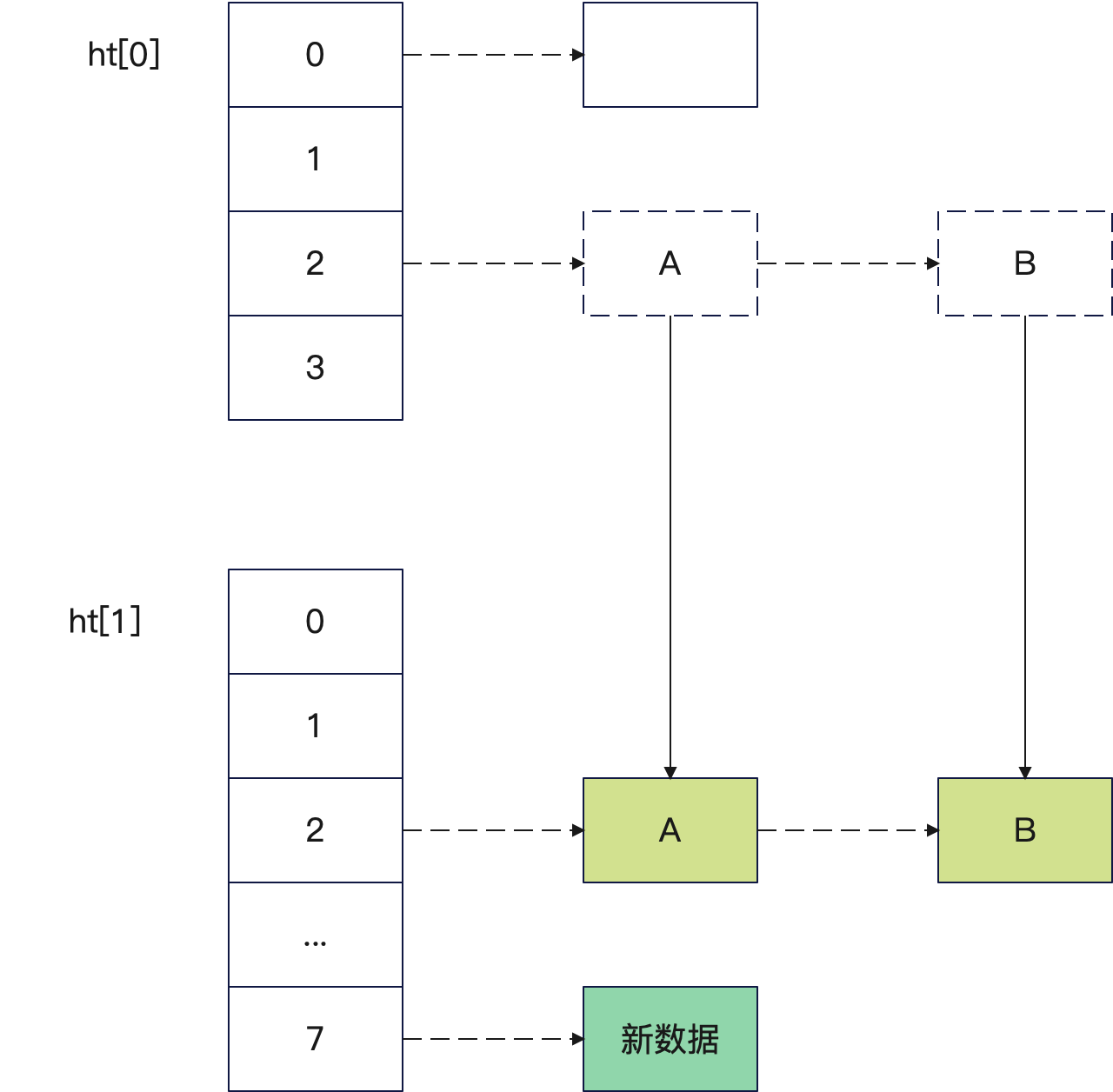
下图则是演示了当出现了增删改查的时候,逐步迁移数据:
但是要注意的是,每次触发迁移的时候,可以迁移多个,也可以迁移一个,取决于 Redis 的配置。
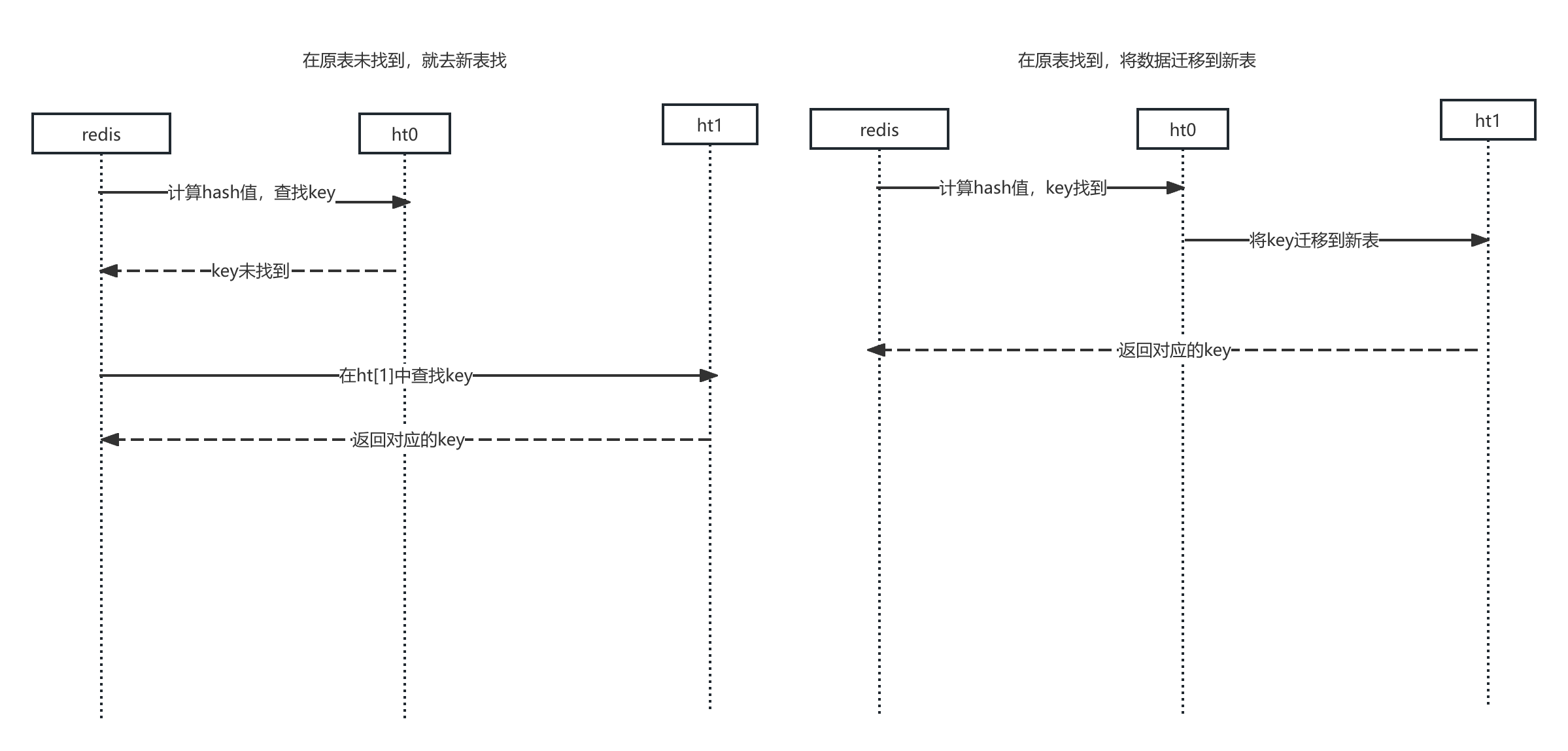
在读取操作中,Redis 会通过提供的键计算哈希值,找到哈希表中对应的位置。接着,Redis 遍历该位置的链表,直到找到与提供的键匹配的键值对,并返回对应的值。如果此时恰好rehash,会先去旧表中,找不到再去新表。在旧表中找到会把数据迁移到新表。如下图所示
我要额外强调一点的是古早很多的八股文都说增删改会触发迁移,但是查询不会。但是在高版本的 Redis 实现中,查询也会触发,你可以从源码中全局检索 _dictRehashStep 来确认渐进式哈希触发的点。
此外,为了加快渐进式 rehash,Redis 还会在后台任务循环中执行主动迁移,迁移 1ms,能迁移多少就迁移多少。
当 ht[0] 中的数据都迁移到了 ht[1] 的时候,直接交换指针,也就是让 ht[0] 指向扩容后的哈希表,ht[1] 置为 NULL。
因此,这里我总结一下 Redis hashtable 实现的要点: