略难的题,难点在你可能很难理解连锁更新的问题,一般不太常问。
注意在这个问题底下,你要先解释 ziplist 的基本结构,而后进一步解释连锁更新。目前来看,能够清晰解释连锁更新的原因、后果就差不多能赢得竞争优势了。
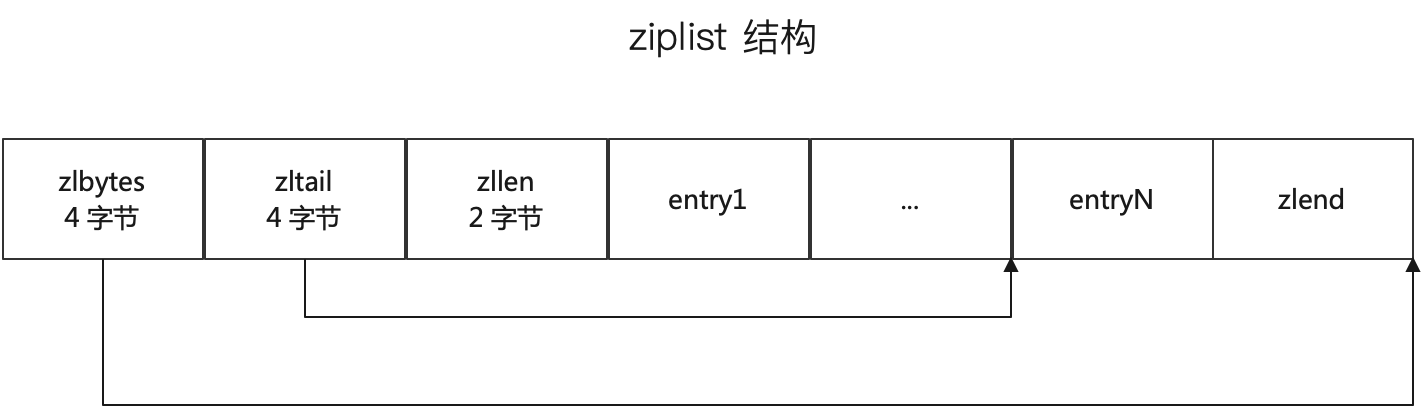
ziplist 是 Redis 中一种紧凑型的列表数据结构,主要用于存储元素数量少且每个元素较小的数据。它通过连续的内存空间来节省存储空间,适用于实现散列表(hash)、列表(list)等数据类型。
ziplist 的结构如上图,一句话就能说清楚 ziplist,它就是一个元素大小不等的数组。而后额外记录了总字节数,尾指针而已,没啥稀奇的。
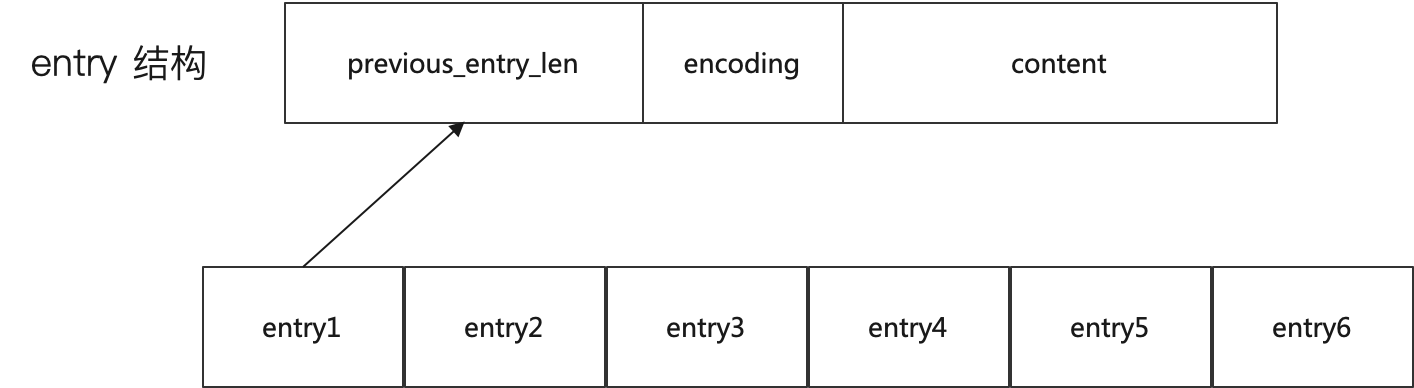
每一个 entry 大小不一,整个结构如图:
它里面有三个字段:
它最大的优点就是节省内存,访问高效。
这里有一个小问题,就是为什么它要记录前一个字段的长度?答案就是出在 zltail 记录的是尾指针,所以它加上这个字段就可以实现从后往前遍历。
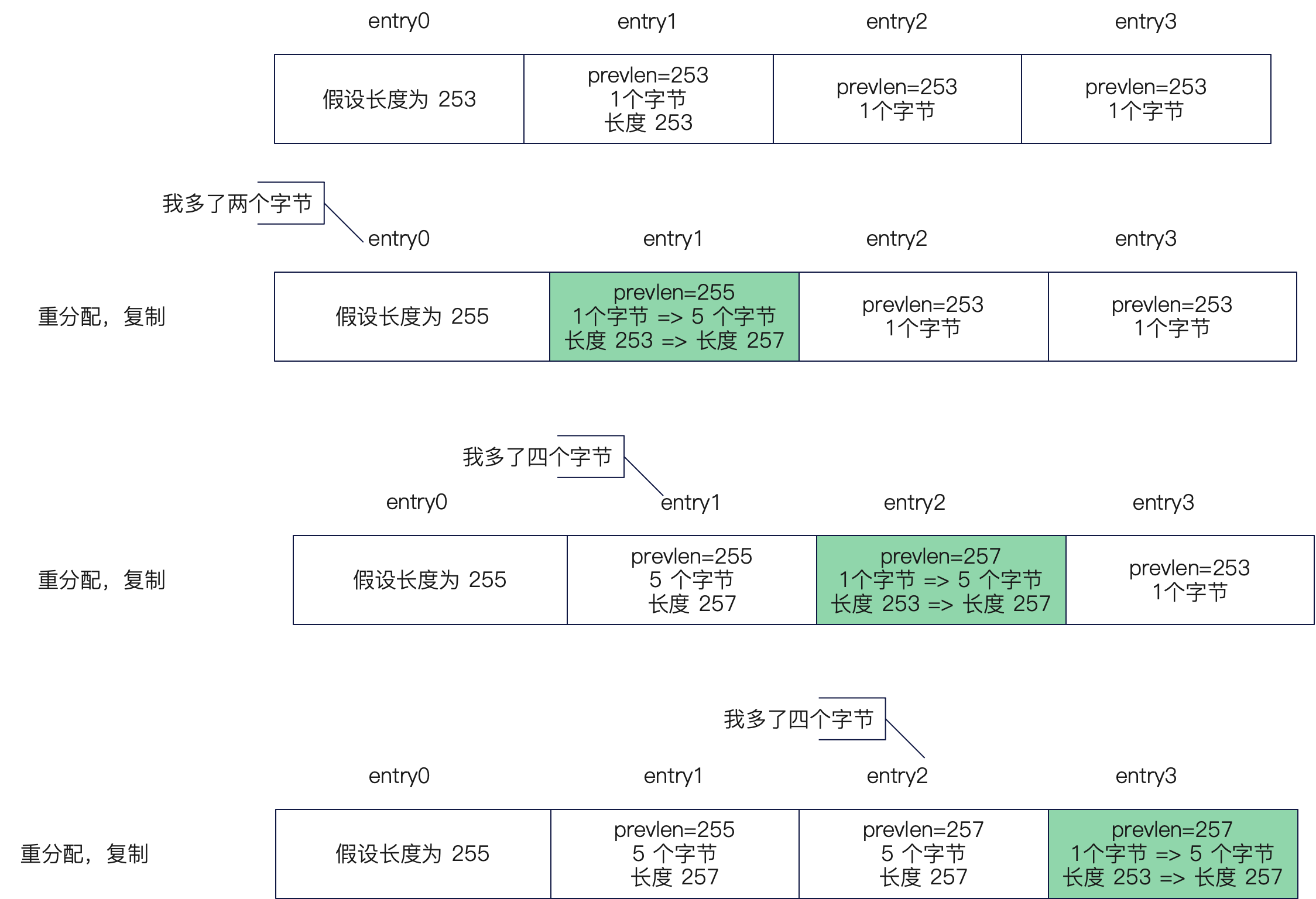
但是偏偏这个 prevlen 字段是一个天坑,它是动态的。也就是说,如果你长度比较小(< 254),它就用一个字节来记录,如果你长度比较长(>= 254),它就用五个字节来记录。
所以你就会发现,如果要是我的 content 原本很短,后来变长了,你长度不就要从 1 字节变成 5 字节吗?跟进一步,如果要是因为上一个长度需要改用 5 字节来记录,导致我自身长度也恰好超过 254,那么我的下一个 entry 岂不是也要改用 5 个字节来记录我的长度了吗?
这就是臭名昭著的连锁更新问题。下图展示了连锁更新的问题:
要注意的是,因为 ziplist 是连续内存,所以这种更新都要重新分配内存,然后把数据复制过去。
这也导致了连锁更新的性能极差,成为 ziplist 最大的缺点,所以后续 Redis 又引入了 listpack 来优化,主要就是为了规避连锁更新的问题。